
ADLS Gen2 and Immutability
Data analytics is all the rage right now. Even in a pandemic affected economy, companies are still using their precious resources to push forward analytics projects that will, in theory, give them “intelligence” surrounding their business and allow them to make more appropriate decisions in to the future. One key component of any data analytics solution is the need for access to data, and this is typically solved by creating a data lake. In Azure, the Azure Data Lake Generation 2 (ADLS Gen2) is the service of choice for storing large amounts of data.
As companies start to move all their data to a central location, they realize benefits in a single management plane for all types of data. A single place to secure, a single place to look, etc. Unfortunately, this also comes with the security downsides of … a single place to delete. Often is the case that the data in the data lake may be the only copy of the data. This is especially true as IT systems undergo lifecycle changes. Further, the cost of restoring data from source systems is now more complex. Not only do you require a target environment to do the restore to, you need to factor in data transit costs (to the data lake), and any post-processing that renders that data usable for your data analytics needs. It’s logical to think that, shortly after data lakes are implemented, companies start to discuss how to secure the data in the data lake.
One relatively new feature in the arsenal for defending and protecting data lakes is the idea of immutability. This becomes especially important as the amount of data increases, rendering traditional ideas around backup moot. In fact, most data lake providers will actively discourage the idea of backup for the very reason of “the data is big”. The existing solution? Enforce proper role-based access controls and hope for the best. Luckily, Azure has just announced the preview of immutable storage for data lakes which gives us another tool to help protect our data.
What is Immutability?
As per the blob storage documentation, immutability is the implementation of a WORM topology on your data lake. WORM stands for write-once-read-many. The idea is that, as per the policies users would define on their data, the service would guarantee that blobs can only be created and read, but never deleted or modified. The important part here is that service guarantees it, and this works even if the user executing the delete is an administrator or has been granted appropriate rights to delete.
In it’s current implementation, there are two types of policies you can apply to enforce immutability. The first is time-based, whereby you can specify a retention period for blobs. These blobs are then stored for that duration. The second is legal hold, which is effectively a non-time based hold on data. It is important to note that both of these policies are applied at the container level and, as long as a file or blob in that container is in the immutable state, prevent deletion of the blob, the container, and the storage account.
You can read more about immutable blobs here.
You can read more about how to implement/try this feature here.
Changes to architecture for ADLS Gen2
Most data lakes follow a structured layout for folders that assist with the extract-transform-load process and the presentation process. For example, you could expect to have the following example layout.
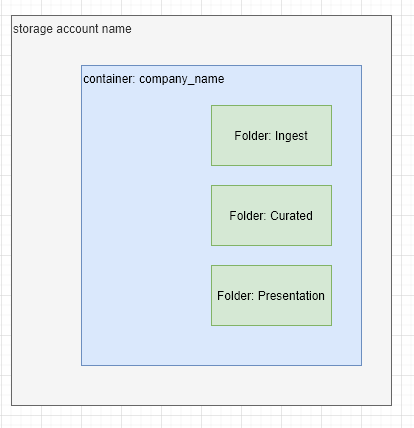
Typically, access control list permissions are applied at the folder level to govern access. Because granular access can be applied, you wouldn’t typically see many containers or storage accounts being used.
In it’s current implementation, immutability policies are storage container level constructs, and thus, we would likely see a push for moving folders inside the data lake to be containers on the storage account. This could also be supported by the fact that there no more limits on storage account containers.
Moving to containers could provide additional benefits, for example, by allowing for all access to be controlled via Azure RBAC, rather than using the POSIX style controls. However, there is still a maximum amount of RBAC assignments you can have, which is set to 2000. So the balance here needs to be considered carefully.
Conclusion
Immutability has been a long awaited feature for ADLS Gen2, and it’ll still be a little bit before it becomes generally available. It is a great alternative to any backup solution which would require you to duplicate your data in order to protect it. Now is the time to start considering how you want to use this feature, and what architectural changes you’ll need to make to your data lake to support it.
About Shamir Charania

Shamir Charania, a seasoned cloud expert, possesses in-depth expertise in Amazon Web Services (AWS) and Microsoft Azure, complemented by his six-year tenure as a Microsoft MVP in Azure. At Keep Secure, Shamir provides strategic cloud guidance, with senior architecture-level decision-making to having the technical chops to back it all up. With a strong emphasis on cybersecurity, he develops robust global cloud strategies prioritizing data protection and resilience. Leveraging complexity theory, Shamir delivers innovative and elegant solutions to address complex requirements while driving business growth, positioning himself as a driving force in cloud transformation for organizations in the digital age.