
Azure Databricks Diagnostic Logs
Azure Databricks implementations follow a fairly typical pattern in terms of a multi-user application deployment. The initial phases are all about delivering some type of business value that attracts users to the platform and encourages them to use it. Once you’ve made it that far, the focus often shifts to understanding how the service is being used. Data driven organizations/projects use this information to fuel decisions around optimization and further feature development. While the Azure Databricks platform offers some built-in reporting capabilities, they are generally operational in nature. The goal of this post is to discuss how to use diagnostic logs to gain insight in to how users are making use of your Azure Databricks workspaces. Diagnostic logs are a great way to aggregate this data across workspaces to get a holistic view of use.
What are diagnostic logs?
Diagnostic logs, sometimes called resource logs, is a feature of Azure services whereby those services emit information about activities that occur “on the data plane” of that Azure service. It is important to note that diagnostic logs are service specific, and each service has a different set of information that can be emitted. While you can forward these logs to a variety of destinations, typically one uses log analytics as a destination.
You can read more about these logs here.
In the case of Azure Databricks, the following logs are forwarded:
- DBFS
- Clusters
- Pools
- Accounts
- Jobs
- Notebooks
- SSH
- Workspace
- Secrets
- SQL Permissions
A couple of key notes:
- I was unable to find a detailed list of all the events that get logged within the categories above. So building reporting is a trial/error process
- The SLA on logs getting in to log analytics is 24hours, which is vastly different from most other Azure services. You basically can’t use this method for real-time (or near-real time) reporting. Which is a shame.
- Many of the fields are actually raw JSON, so you will get familiar with the parse_json KQL command.
If you want to learn more about how to enable diagnostic logs, please see this link.
Let’s discuss a couple of these logs in more detail.
Diagnostic Logs - Databricks Accounts
The Databricks accounts log captures events surrounding logins to your various workspaces. While most logins will either be of type “Microsoft.Databricks/accounts/tokenLogin” or “Microsoft.Databricks/accounts/aadBrowserLogin” I’d expect more login types soon as features such as ServicePrincipal login comes out of preview.
One interesting query here is to group the logins via UserAgent.
DatabricksAccounts
| summarize count() by UserAgent
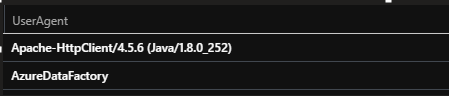
You can see that for this particular workspace, most of the usage is Apache-HTTPClient which I can only assume is the databricks workspace itself. This is likely tied to how jobs are handled/run in the backend. The second is AzureDataFactory which is likely due to Data Factory being used as the ELT orchestration engine.
You can also run other queries to figure out who these users are by looking at the identity field. For example:
DatabricksAccounts
| where ActionName contains "login"
| extend d=parse_json(Identity)
| project UserEmail=d.email, SourceIPAddress
Diagnostic Logs - Databricks Notebooks
The notebooks diagnostic logs can be interesting when you want to understand how notebooks are being used in the organization. Typically, one creates a couple of workspaces for different purposes. An analytics workspace is more for analysts doing one-off work, whereas your engineering workspaces are more to support your ETL processes. As such, I’d expect to see lots of creates in the analytics workspaces, but little to none in my engineering workspaces (unless a code deploy was done).
Some sample queries that could provide some insight:
DatabricksNotebook
| where ActionName == "createNotebook"
| summarize count() by ResourceId
It would help you understand where the majority of your notebook creation is happening. If you wanted to understand who is creating these notebooks, you could run something like:
DatabricksNotebook
| where ActionName == "createNotebook"
| summarize count() by Identity
You may want to also understand which notebooks the operations are occurring on. You could use a query like the following to pull out the notebook name:
DatabricksNotebook
| extend requestJSON = parse_json(RequestParams)
| project notebookName = requestJSON.path
Conclusion
There is a wealth of information that is contained in these diagnostic logs. A key part of your infrastructure deployment should be to forward these logs to a log analytics workspace so you can start to perform this type of analysis. Hopefully this post was enough to get you started on your journey.
About Shamir Charania

Shamir Charania, a seasoned cloud expert, possesses in-depth expertise in Amazon Web Services (AWS) and Microsoft Azure, complemented by his six-year tenure as a Microsoft MVP in Azure. At Keep Secure, Shamir provides strategic cloud guidance, with senior architecture-level decision-making to having the technical chops to back it all up. With a strong emphasis on cybersecurity, he develops robust global cloud strategies prioritizing data protection and resilience. Leveraging complexity theory, Shamir delivers innovative and elegant solutions to address complex requirements while driving business growth, positioning himself as a driving force in cloud transformation for organizations in the digital age.