
Exploring Azure SFTP for Blob
If you work in the data space, you’ll inevitably come across situations where you need to use the SFTP protocol to move data around. Typically used for movement of larger files (or, re-importing data, etc) SFTP can be a useful tool and one that you should really plan for in your data environment. Further, many full solutions exist to manage the movement of files over the SFTP protocol. If you have a cloud native mindset, like me, you have probably sighed at the requirement for SFTP. In the past in the Azure world this requirement meant standing up a virtual machine (and building all related automation) to support the SFTP process. If this was core to your data pipeline strategy, you also had to think about load-balancing, high availability, DR, etc of the solution.
The good news is that Azure Blob Storage now has an SSH File Transfer Protocol Endpoint which can help to simplify the architecture of providing SFTP services into your Azure environment. The goal of this post is to review and discuss the current offering.
SFTP Architecture
From a cloud architecture perspective, the task that the cloud providers are trying to do when offering SFTP directly into storage is translate the SFTP protocol (and features) into blob storage calls. Thinking about this in terms of cloud patterns, they are effectively trying to create an ambassador around the storage service. You can read more about the ambassador pattern here. Taking into account the existing architecture of cloud storage, there are likely two patterns that a cloud provider could follow to service this capability.
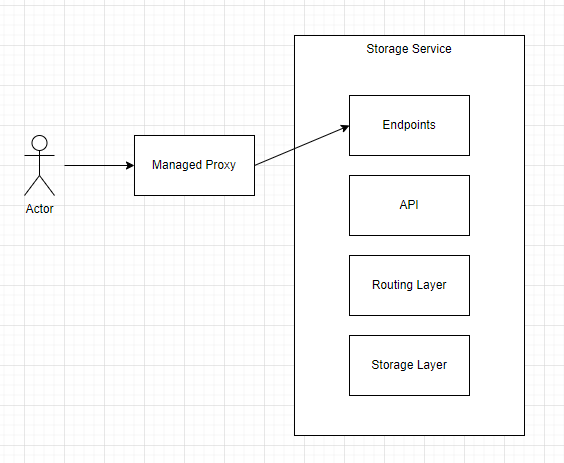
In the example above, the cloud provider effectively puts a managed proxy in-front of the storage service. There are several advantages to this type of approach. For example, the managed proxy itself can be moved independently of the storage service itself, allowing one to imbed the proxy inside their network. The disadvantage, of course, is that there is now another component that needs to be managed. The cost of doing so needs to be put onto someone (likely the customer). Think about this in terms of network connectivity, disaster recovery, etc.
The second pattern looks more like this:

In this pattern, the API that implements the storage service has been extended to incorporate a translation layer (or service, or set of servers, etc) that translates SFTP commands to backend instructions for the storage service. Because the storage service itself has been expanded to support this new feature, the feature inherits all the properties of the existing service but becomes harder to customize and, maybe, implement in certain scenarios.
What is interesting about the discussion above is that pattern 1 describes how AWS decided to do SFTP to S3 (Via Transfer Family) and pattern 2, at least from reading the docs, appears to be how Azure has decided to implement the service.
Other Notes
The Azure SFTP service is still currently in preview and so here are some other random thoughts about the service (from reading the documentation)
- Only local users are available. This means that there is no tie-in with existing authentication mechanisms such as Azure Active Directory
- The currently supported set of algorithms seems robust and is based on Microsoft’s Security Development Lifecycle (SDL)
- Host key integration/support seems suspect. You’ll have to get used to the fact that (at least in preview) host keys on the SFTP service are rotated monthly. This might weaken a core security aspect of SFTP
- Currently operates only at the container level and ignores any POSIX rules you may have. This likely means that you are creating containers for each of your users (which isn’t that big of a deal)
Conclusion
I’ll likely look into setting this up and playing with it some more in the future. It seems like an interesting design decision to implement SFTP the way they did and I am eager to experience the trade-offs first hand. I hope you enjoyed the post.
About Shamir Charania

Shamir Charania, a seasoned cloud expert, possesses in-depth expertise in Amazon Web Services (AWS) and Microsoft Azure, complemented by his six-year tenure as a Microsoft MVP in Azure. At Keep Secure, Shamir provides strategic cloud guidance, with senior architecture-level decision-making to having the technical chops to back it all up. With a strong emphasis on cybersecurity, he develops robust global cloud strategies prioritizing data protection and resilience. Leveraging complexity theory, Shamir delivers innovative and elegant solutions to address complex requirements while driving business growth, positioning himself as a driving force in cloud transformation for organizations in the digital age.