
Microsoft Identity Platform: OAuth Basics Pt.2
Read any OAuth documentation, and they go at length to discuss the fact that OAuth is not an authentication protocol. While there are authentication steps embedded within the OAuth protocol (for example, authenticating a client application before granting it an access token), none of these authentication steps are valid for end-user authentication.
To understand this a bit more, we have to discuss the OAuth dance. As I mentioned in my last post, there are several great resources on the internet that discuss this, so I’ll just provide an overview for reference sake. This overview will be focused on the authorization code grant type, which is one of the most common grant types used today.
Step 1: The client redirects the resource owner to the authentication server. The client provides details about who it is (remember that clients are pre-registered in OAUTH) and the request for authorization (typically handled via the use of scopes).
Step 2: The authentication server authenticates the user and processes the authorization request. It returns an authorization code to the pre-configured redirect URI for the client.
Step 3: The client uses the authorization code and its own credentials in a request to the authentication server. The authentication server responds with an access token that encompasses the grants it needs to the target protected resource.
Step 4: The client uses the access token against the protected resource to verify its level of access and makes the protected/restricted calls.
There are a couple of significant issues with this flow related to the authentication of the end-user. The first one is the fact that the client doesn’t actually know who the user is. Remember, as far as it is concerned, it is returned an authorization code that contains no information. It exchanges that code for an access token. None of this suggests (or should suggest) who the user is. OAuth is designed so that both the authorization code and the access token are opaque to the client.
The second one is that this whole flow does not give the protected resource any understanding of how the user was authenticated, or even if the user is still there. From the protected resource standpoint, it receives a valid access token that contains a set of claims. This may be a long-lived access token, and the access token may even have a refresh mechanism. All the resource provider can deduce at this point is that the user, at some point, authorized this client to make calls on its behalf.
OpenID connect
As per the OpenID Connect FAQ (https://openid.net/connect/faq/)
“OpenID Connect lets developers authenticate their users across websites and apps without having to own and manage password files. For the app builder, it provides a secure verifiable answer to the question: “What is the identity of the person currently using the browser or native app that is connected to me?”
Stealing again from OAuth In Action (I highly recommend reading this book), the following layout is applied in the OpenID Connect pattern.
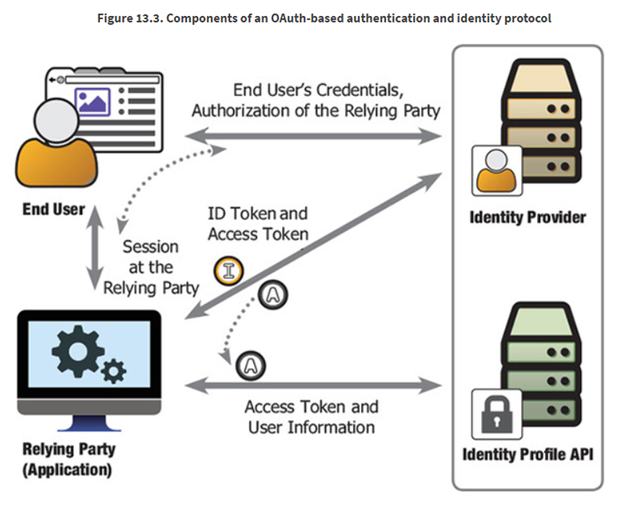
Some important notes:
· Identity profile information is treated like a protected resource (from an application perspective). OAuth is used here to issue an access token which the application can then use to get further information about the logged-in user.
· A separate ID Token is sent along-side an access token. This provides the relaying party (or the client application in OAuth parlance) a parse-able token that gives enough information about the login event to make authentication decisions.
There is a lot more to OpenID Connect than what we talked about above, but the basics there allow you to understand why this protocol is essential and how it leverages OAuth.
With the basics out of the way, we can now start diving into Microsoft Identity Platform’s specifics.
About Shamir Charania

Shamir Charania, a seasoned cloud expert, possesses in-depth expertise in Amazon Web Services (AWS) and Microsoft Azure, complemented by his six-year tenure as a Microsoft MVP in Azure. At Keep Secure, Shamir provides strategic cloud guidance, with senior architecture-level decision-making to having the technical chops to back it all up. With a strong emphasis on cybersecurity, he develops robust global cloud strategies prioritizing data protection and resilience. Leveraging complexity theory, Shamir delivers innovative and elegant solutions to address complex requirements while driving business growth, positioning himself as a driving force in cloud transformation for organizations in the digital age.