
ADLS Gen2 and File Snapshots
Microsoft is working quite hard to bring Azure Data Lake Gen2 features in line with those of blob storage. One of the latest ones is file snapshots, currently in public preview. The goal of this post is to discuss file snapshots. It is important to note that file snapshots are only in certain regions right now, and you have to fill out a form to have it enabled for your subscription.
What are file snapshots?
A file snapshot is effectively a full copy of a set of blobs (as it relates to a file) with only one change, the name of the file is updated to contain the date and time of the snapshot itself. A file itself can have an unlimited amount of snapshots, and you are charged for the extra storage as the source file diverges from the last snapshot taken. Here is a look at how snapshots are surfaced in the portal.
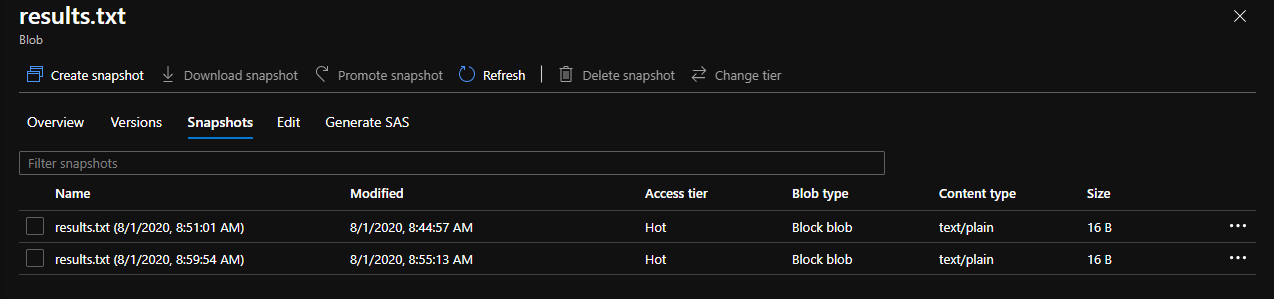
At this point, the file snapshots are implemented via the blob API, and allow for all the standard blob operations you would expect including changing tiers, deleting snapshots, etc.
Snapshots have a “promote snapshot” feature which allows you to replace the current version of the file with the desired snapshot. Interestingly, this process is more similar to updating a file pointer than it is to doing operations such as a copy. Going “back-in-time” does not actually delete any of the other snapshots, allowing you to go back and forth pretty easily.
Another interesting point is around deletes. The blob storage subsystem does not let you delete a blob that has snapshots. This works the same through the blob API and the DFS API.
Request URL:
https://shamfilestoragetest.dfs.core.windows.net/test/results.txt?recursive=true&_=1596375806137
Request Method:
DELETE
Status Code:
409 This operation is not permitted because the file has snapshots.
However, it did not prevent me from deleting the container itself or the parent folder. Further, the snapshots were not visible via the DFS APIs (only the blob ones), so you don’t see them in storage explorer.
File snapshots are basically a manual version of blob versioning (also in preview, but not for ADLS Gen2 yet).
Random Thoughts
Originally, I had considered file snapshots as an easy way to achieve backup in my data lake without having to make multiple copies of the data in different containers and accounts. It seems like file snapshots is not designed for this purpose. This is mainly due to the fact that deletes at the folder and container level are not prevented if snapshots exist.
While I agree that there may be some interesting use cases for file snapshots, particularly around changing data, most of my clients make use of features inside of delta to achieve the same thing.
As a snapshot is effectively just a blob api call, currently the REST API allows for a bunch of the same headers as blob creation. This could be useful when keeping track of your snapshots, by allowing you to add user metadata.
I think it would be an interesting default that when you are restoring a snapshot version, the current file is itself snapshotted prior to the operation. This would help in the case of accidental clicks where the current version is lost forever. This obviously has cost implications, and could maybe be something that is configurable.
It would be nice to see policies for snapshots (and other features such as versioning, encryption) be a folder level construct, rather than a blob, container, or storage account construct. There are many issues when it comes to scaling a data lake, and thinking of folders as first-party citizens might make much for sense.
Conclusion
The purpose of this post was to review file snapshots. I took it for a quick test drive to understand it’s use cases and application to my problem areas (mainly backup). Unfortunately, it doesn’t seem like file snapshots are going to solve the backup problem, and we will have to wait for other features and services to come available in the future.
About Shamir Charania

Shamir Charania, a seasoned cloud expert, possesses in-depth expertise in Amazon Web Services (AWS) and Microsoft Azure, complemented by his six-year tenure as a Microsoft MVP in Azure. At Keep Secure, Shamir provides strategic cloud guidance, with senior architecture-level decision-making to having the technical chops to back it all up. With a strong emphasis on cybersecurity, he develops robust global cloud strategies prioritizing data protection and resilience. Leveraging complexity theory, Shamir delivers innovative and elegant solutions to address complex requirements while driving business growth, positioning himself as a driving force in cloud transformation for organizations in the digital age.