
Communication Security and Azure Databricks
We are going to continue on exploring security considerations with Azure Databricks. In this post, I’m going to touch on communication security and how it is handled within the various components that make up the Azure Databricks service.
Communication security is particularly important when using cloud services. Most regulations and cyber security frameworks will expect that data (sensitive in nature anyways) be protected both at rest and in transit. What they typically mean by that is that both the integrity and the confidentially of data is protected while it is transmitted. In communication channels, this is generally enforced using something like transport layer security (TLS) but not always.
In order to structure our discussion, lets consider the following diagram which outlines the major components of the Azure Databricks solution (including expected integrations).
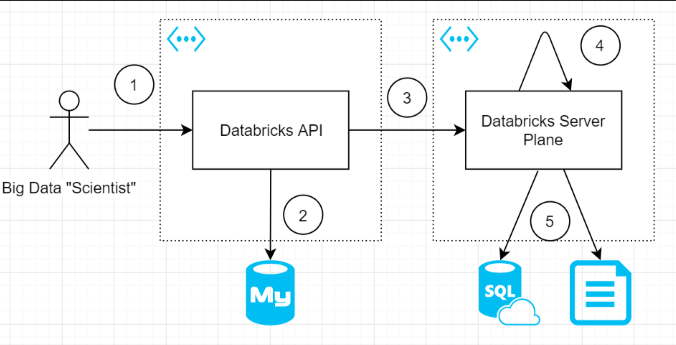
Link 1: User to Azure Databricks API
Whether you are using the portal, or using the databricks-cli, you are effectively interacting with the Azure Databricks API. This is a multitenant component that is controlled by Databricks and Azure.
From a transport security perspective, the connection to the Databricks API makes use of TLS. In fact, it receives a A+ rating from SSL Labs. Reading through the report, many things are done really really well, which is amazing to see. For example, only TLS 1.2 and 1.3 are currently supported, and 6 of 7 algorithms are considered strong.
Since the Azure Databricks API is backed by Azure Active Directory, currently the only way to limit access to the API itself is to make use of conditional access. I have heard whispers of upcoming features that will allow you to control access to the workspace by way of IP whitelisting.
Link 2: Databricks API to MySQL
The Azure Databricks service makes use of MySQL to store state about events occurring in the workspace. This includes the results of notebook operations, so sensitive data could be stored there as a result of workbook execution.
As this link is hidden within the Databricks service itself, there isn’t a ton we can do to inspect the security. We do know that the MySQL service in Azure is encrypted by default, uses authentication by default, and has firewall services. It is safe to assume that all 3 of these are in use.
Link 3: Databricks API to Databricks Server Plane
When you use VNET injected clusters, you need to create a subnet with a NSG attached that Databricks can control. As per the documentation Databricks strictly controls inbound communication to only originate from the Databricks service by use of service tags.
The only 2 inbound ports from the Databricks API is port 22 (likely SSH) and port 5557. According to all public documentation, TLS is used to communicate between the API and the configured clusters.
Link 4: Databricks Server to Server Communication
As per the documentation traffic between server nodes is not encrypted. This means that you are left with writing some init scripts to configure this properly. The documentation covers the basic steps and you can review the spark security guidance for more information.
Link 5: Databricks Server to Other Services Communication
Typically, your Databricks cluster doesn’t act on it’s own, and needs data sources (such as Azure Data Lake Gen2) and data syncs (such as Azure SQL) in order to operate fully. If you deploy your Databricks with VNET injection, then you can make use of other Azure features such as service endpoints and private links to secure communications. You can read more about this here.
Conclusion
In conclusion, it is important to understand how PaaS services work, especially from a security perspective. While the concepts of a shared responsibility model are important, exercises such as the one we just completed are important to understand where security considerations are handled by the provider and where there is still work to do on the client end. I’d wager a guess that link 4 often gets missed during security reviews.
About Shamir Charania

Shamir Charania, a seasoned cloud expert, possesses in-depth expertise in Amazon Web Services (AWS) and Microsoft Azure, complemented by his six-year tenure as a Microsoft MVP in Azure. At Keep Secure, Shamir provides strategic cloud guidance, with senior architecture-level decision-making to having the technical chops to back it all up. With a strong emphasis on cybersecurity, he develops robust global cloud strategies prioritizing data protection and resilience. Leveraging complexity theory, Shamir delivers innovative and elegant solutions to address complex requirements while driving business growth, positioning himself as a driving force in cloud transformation for organizations in the digital age.